10+ Concurrent Validity Examples to Download

Do exam grades measure learning? Validity tests convert an abstract idea?—here, learning, into something measurable and quantifiable: the child’s performance rating after taking the written exam on the subject. But written tests, we realize, aren’t the only way we can measure how much the child understood. However, we can’t just adopt any assessment method. We have to know if the approach is as telling as the present valid and reliable method we have: Enter concurrent validity.
Concurrent validity is the measure of a test’s prognostic capacity of a case in relation to a standard test. The standard test is established and highly valid. Therefore, the newer measure, stacked against the former, would also be valid. You have to perform both tests concurrently or simultaneously. Otherwise, you would be gauging the predictive validity of the newer test. Concurrent and predictive validity tests evaluate the prognostic power of an assessment. These, together with other validity tests, are important in social and behavioral sciences.
From Principle To Practice
For example, you want to create a test that measures the scholastic performance of students enrolled in a new learning program. You have to make sure that your assessment method?—in this case, the test itself, is valid in measuring the performance. Therefore, you will use an existing and related examination that was already proven to be credible and reliable for such an assessment. When the students fare well in both tests, your new test is valid in measuring what the benchmark test measured.
In psychology studies, researchers may need to employ new means of collecting or analyzing data for their study. Their new method should be appropriate. Even if it seems similar in principle with the standard method, they have to perform reliability and validity checks to make sure. Defend that for your study, there is an insignificant difference between the data that you have obtained from both methods.
One criticism against concurrent validity is that it is only as good as the standard test you measured it against. Therefore, whatever flaws and inconsistencies prevalent in the old test might also be present in the new one. The contention exists in the accuracy of the tests in assessing the intended construct.
10+ Concurrent Validity Examples
The following are examples of concurrent validity as used in research papers.
1. Concurrent Validity and Reliability Example

2. Construct and Concurrent Validity Example

3. Concurrent Validity of Questionnaire Example

3. Sample Concurrent Validity Example
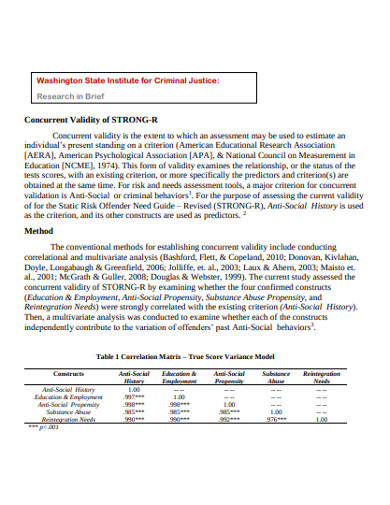
4. Basic Concurrent validity Example

5. Standard Concurrent Teacher Assessment Validity

6. Concurrent Validity of Personal Test Example

7. Factor Analysis and Concurrent Validity Example

8. Concurrent Validity Quality of Life Questionnaire

9. Concurrent Analysis Validity Example

10. Standard Concurrent Validity Example

11. Printable Concurrent Validity Example

Testing for Concurrent Validity
This criterion validity measure evaluates the validity of the new test by performing it simultaneously with the standard test, then measuring the correlation between the two.
1. Concurrent Data Collection
The difference between concurrent and predictive validity lies only in the time which you administer the tests for both. A few days may still be considerable. The simultaneous performance of the methods is so that the two tests would share the same or similar conditions.
2. Cronbach’s Alpha Coefficient
Before we can find out if the data we collected are valid, we have to check first if they are reliable. There are different reliability tests that evaluate for the internal consistency of your data between the two methods. For the purpose of this article, we will use the Cronbach’s alpha. From 0 to 1, the standard coefficient of reliability should be more than 0.7. You will have a coefficient of 0 when the data are independent. Increasing coefficient value means the data from both may be related.
3. Convergent Validity Test
After, proceed to analyze the data and examine if the new test is valid. You can go with convergent or discriminant validity tests. Both will provide a similar measure of validity. For convergent validity, the higher the correlation value, the higher the validity of the new test is. This test assesses how related the old and the new methods are in theory and in practice. This means that the standard test and the new version measure the same construct and are related.
4. Discriminant Validity Test
The lower the correlation value, the higher the validity of the new test. In the discriminant validity assessment, the tests are measuring distinct or different kinds of constructs. The standard test measures one thing while the new test measures another. Since you are testing for the validity of the newer assessment method against how much it is similar to the standard method in measuring a construct, it is vital that both tests examine the same construct.
Share :
