10+ Predictive Validity Examples to Download

Since 1948, those who dream of being lawyers, from college students to young professionals, have been studying day in and day out to get a score of 160 or higher in the Law School Admission Test (LSAT). But, do these one-time exams actually determine your success in law schools? Predictive validity measures maintain that valid tests can predict, to a certain degree, a person’s performance over something set in the future.
Like concurrent validity, predictive validity tests an assessment against a criterion. Unlike concurrent validity, this criterion exists in the future. When the measurement we created has high predictive validity, we will be able to forecast a future scenario based on our understanding of the construct. We must understand what we are trying to predict.
Role of Predictive Validity
We can’t predict the future with complete certainty. If so, why is the concept of predictive validity even thriving today?
In The Academe
We can best illustrate the concept using the idea behind school admission tests. First, we define the determinants of a construct, for example, success in school. We apply these determinants in the exam, like preparedness for the test. Therefore, we measure their success by how prepared they are for the exam. Those who have studied well for the test will earn higher marks. We can also factor in diligence as the amount of effort they put in high school as reflected in their grades. Those who were diligent in high school may also be diligent in college and earn good marks.
In The Business
The business industry also uses predictive validity, especially during employment. Companies can give tests to job applicants to determine their qualifications for the job, aside from looking at their resume and CV. Entrance exams let the management have a feel at how the job candidate may perform in his or her job. The results can also be used to evaluate if the person actually fared in his or her work. When companies find that their initial assessment of a significant number of employees did not correlate with the persons’ work performance, it is time to change how businesses screen future applicants. Low predictive validity can mean the companies are letting go of potentially skilled candidates due to a flawed screening system.
In Animal Research
Predictive validity has played a role in the annals of medicine and animal research. In ethical scientific research, we have model organisms, such as zebrafish, toads, fruit flies, chicken, cats, and mice that we can use to investigate the human body, from early development to senescence. Some of these animals respond similarly to certain treatments as humans. Therefore, we perform treatment tests on these organisms. High predictive validity in animal models indicates that they react to treatments as humans would.
Predictive validity is limited by how we define a construct. That is why it is not a perfect predictor. Maybe our definition of success is based solely on high grades. Or our criteria for the best law school candidates are those with soaring GPAs that we are ignoring if they have the emotional intelligence to survive the degree. Although predictive validity is not perfect, it is still a valid measure.
10+ Predictive Validity Examples
We learn better through example. The following are predictive validity samples as how they are used in research studies.
1. Sample Evaluating the Predictive Validity Example

2. Predictive Validity of Study Example

3. Internal Consistency and Predictive Validity Example

4. Construct and Predictive Validity Example

5. Multilevel Assessment of Predictive Validity Example

6. Judgment PredictiveValidity Example

7. Meta-Analysis of the Predictive Validity Example

8. Predictive Evidence Validity Example

9. Final Exam Predictive Validity Example

10. College Admission Predictive Validity Example
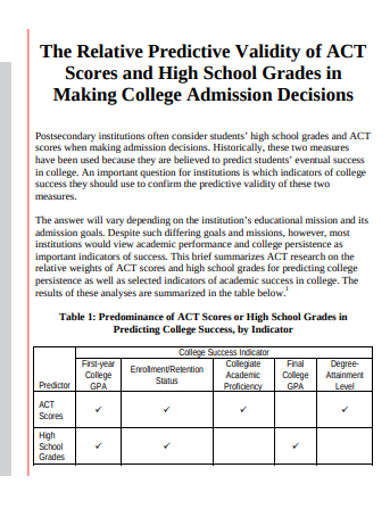
11. Predictive Validity in DOC
Improving Predictive Validity
High predictive validity in tests and measurements can help universities screen the bright and promising students. This also aid employers build a better, talented and dependable team in their company. Our health and life longevity will also improve with the production of better treatments. How do we improve the predictive validity measure?
1. Time Matters
Time is of the essence, in a way. Since predictive validity is concerned with forecasting an effect based on how we define a construct, we need to undertake the assessment within a time period. We have to keep tabs on the progress for the duration of the study. Concurrent validity, on the other hand, produces quicker results.
2. More is Better
To come up with a better result, we have to pool a larger sample size. We need to gather a lot of data so that our results can even be close to conclusive. Because with a smaller sample pool, the outcomes may just be by chance. Therefore, we can make our findings more reliable and better at predicting when it is proven true for a diverse and large number of people.
3. Give Context
Define and be specific about what you want to predict. Do your research on how to best define the construct, for example, reading comprehension. Does fast reading matter? Do you have to take into consideration the faster response to questions? Is good memory recall on the passage important? You have to understand what the construct means and how you can best quantify such an abstract.
4. Do More Research
In relation with the contextualization of the construct, we should always stay updated with recent developments in different industries related to our project. The more we know about the technicalities and governing theories, the better we can contextualize what we want to measure. When everyone else is striving for politcal correctness, we have to abandon antiquated definitions and keep up with the times.
Share :
